
Introduction
There has been a comprehensive amount of tooling designed to enable Twitter research by collecting Tweets using a variety of means. The following tools are often used by researchers:
- Twitter API (with a variety of native and third-party libraries for different languages, including the following Python libraries:)
- Twint
- SciencePo MediaLab’s Gazouilloire
- Gephi’s Twitter Streaming Importer Plugin
However, a limited number of tools specifically aimed at disinformation research currently exist. Second, a limited amount of these tools allow researchers to detect trends in information operations in real time.
Researchers have two choices: to either collect massive amounts of real-time Twitter data and narrow down their research from there, or to collect very specific datasets from past tweets pertaining to specific hashtags, users or terms being employed in ongoing disinformation campaigns.
A third challenge lays in how researchers can actually share this data. Twitter’s Developer Policy specifically prevents researchers from sharing full tweet datasets and are only limited to sharing Tweet IDs.
Developing Simple Twitter Analysis Rules (STAR) is my attempt at building a solution to these challenges: the ability to detect suspicious behaviour in real-time in order to narrow down data collection, and the creation of signatures that can be shared amongst researchers to enable cooperation.
The following repositories have been made public:
- https://github.com/clementbriens/star includes several tools to leverage STAR rules, including scanning Tweets in JSON format and connecting to a Twitter Stream for real-time scanning of tweets
- https://github.com/clementbriens/star-rules includes a number of rules I’ve written for the French elections and the Russian invasion of Ukraine
In my quest to bring together frameworks, tools and methodologies between the fields of cyber threat intelligence (CTI) and disinformation research, such as the Diamond Model of Disinformation, one novel approach has yet to be tested for detecting tweets potentially linked to disinformation actors in real time. Threat intelligence analysts use several rules-based tools that enable a near-real-time detection of threat activity via the detection of malware. Two of the main tools used include YARA rules and Sigma rules.
YARA Rules
YARA rules use malware characteristics to build signatures for specific families of malware, enabling researchers to detect new instance of a type of malware based on previously observed instances of that malware. Several large malware sharing platforms such as VirusTotal allow users to upload YARA rules, notifying them of any new malware samples uploaded to their platform that match the characteristics and conditions specified in their rules.
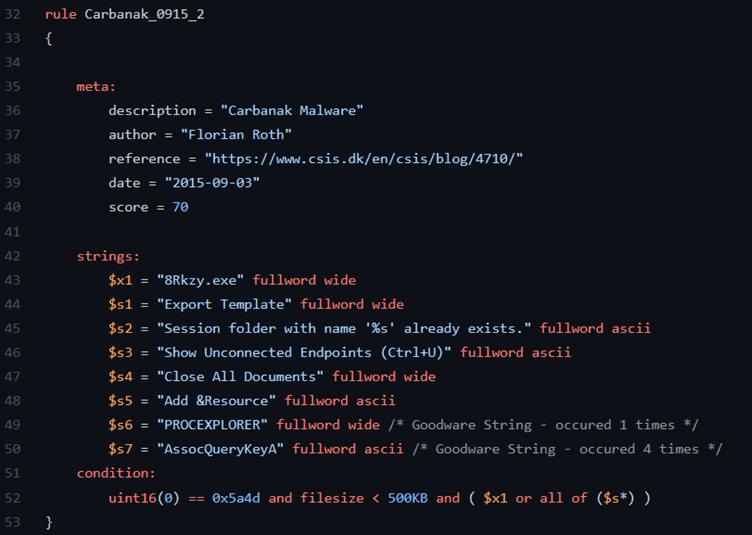
Rules can then be shared to the wider community, enabling more organizations to leverage the rules to detect malware in their own environments, for instance by scanning their devices for malware. Threat intelligence analysts now write and share YARA rules for different malware families, threat actors and suspicious behaviours.
YARA Rules for different threat actors
Sigma Rules
Sigma rules allow CTI analysts to detect suspicious activity on their networks based on behaviour. More specifically, this includes observing logs of network activity within their organisation, such as commands ran by users, processes spawned, and connections to remote servers that have been previously associated to malicious activity. These rules are simple YAML files, enabling CTI analysts to easily write and share rules in a format that is widely adopted.
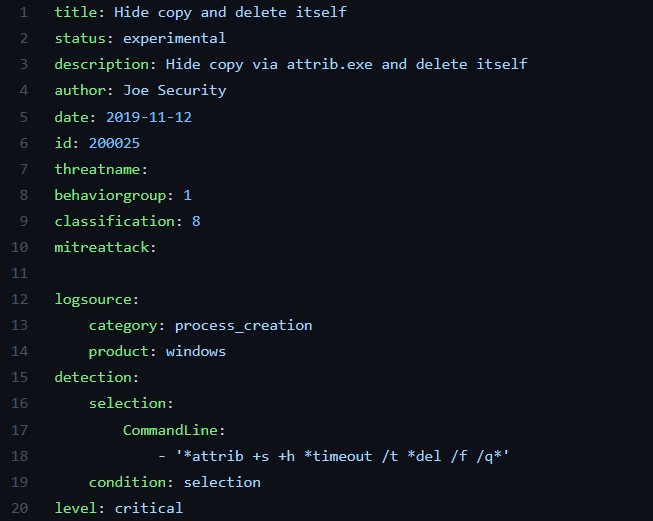
Threat-based vs atomic rules
Both types of rules enable a flexible use by analysts. On one hand, one can use such rules to detect highly specific threats that they are in the process of researching, including specific malware families, threat actors, exploits etc. While these rules prove extremely useful to aid this type of research, their main flaw is that they rely on existing observations of these threats, such as past cyberattacks, indicators, malware samples that have already been collected and analysed extensively.
On the other hand, these rules can be broken down into “atomic” indicators of suspicious activity, which, when combined together, would enable analysts to detect potentially novel threats. This may includes hundreds or thousands of smaller rules which detect a single instance of suspicious behaviour. Malware samples which rack up several detections from these rules can hence be further triaged for further analysis, potentially leading to the discovery of novel threat activity. Atomic behaviours of malware may include:
- HTTP requests to a server
- Using PowerShell commands
- Obfuscating itself
- Spawning new processes
Individually, these behaviours are not suspicious- however, an unknown piece of software which is detected doing three or four of the above on your organisation’s network may be worth investigating.
Building STAR
Having worked extensively with both tools for CTI analysis, I wanted to build a tool for disinformation research that:
- would borrow the signature-based approach of both YARA and Sigma rules, enabling researchers to easily write and share them with the wider community
- would use the simplicity of Sigma’s YAML format for writing rules
- would be able to be used to scan Tweets both locally (historical databases) and remotely via the Twitter streaming API (real-time detection)
- would enable the detection of both threat-specific behaviours as well as the detection of more atomic behaviours
- would hence enable the detection of known disinformation networks and botnets as well as the detection of novel techniques and threats
I’ve hence chosen to build STAR so that it can:
- Use YAML for easy writing/reading/sharing
- Can scan Tweets in JSON format
- Can be used to scan Twitter API streams in real time
- Outputs to CSV files and Elasticsearch for analysis and storage
- Use custom metrics useful for disinformation research that don’t exist natively in the Twitter API, such as detecting an account’s tweeting frequency per day and per week, sentiment analysis, regex etc.
Writing STAR Rules
STAR rules hence use a simple structure, comprising of three main elements: metadata, detections, and a condition.
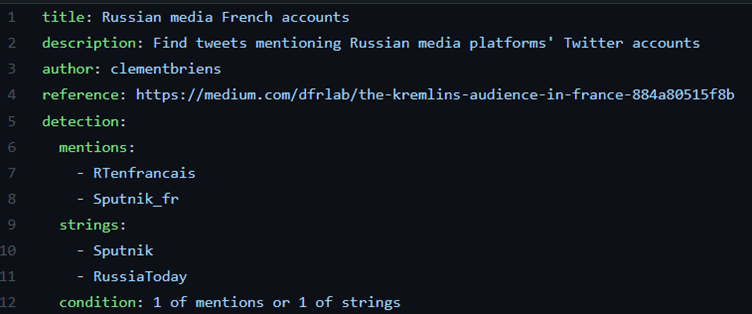
The metadata section consists of information that you would like to attach to the rule for context, including a title, description, author, and a reference. You can also add custom metadata fields under these, such as AM!TT techniques, dates, etc.
The detection section consists of the different fields you would like to base your detection around. The example above includes two fields that we are trying to detect: user mentions and strings in the Tweet text. We are able to specify which specific accounts and strings we’d like to detect. In this case, we’d like to detect users that mention two Russian media platforms’ French-language Twitter accounts or that mention the two media platforms’ names in the text. Four types of detection fields are available:
- String-based detections: allows you to specify which strings to detect in a number of fields, including the Tweet text, author’s screen name, hashtags…
- Math-based detections: allows you to specify ranges or limits for integers in different fields, including dates, number of followers, number of retweets etc.
- Boolean detection: allows you to specify Booleans (True/False) for certain fields, including whether the account is verified, uses a default profile picture…
- Regex detection: allows you to use regex patterns on any string field, allowing you to detect patterns in the text, user handles, etc.
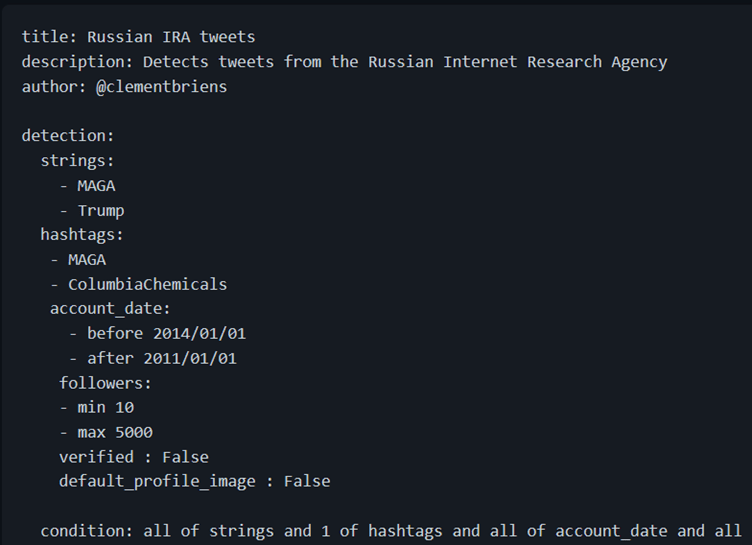
Example STAR Rule leveraging all types of detections

The last required element in any STAR rule is the condition, where you specify the logic by which the rule should trigger a hit based on the specified detections. It uses a human-readable syntax that allows you to pick and choose which detections to leverage when appraising a tweet.
Collection using STAR rules
Once you’ve acquired or written some STAR rules, you can start deploying them using the STAR stream script including in the main STAR repository, which allows you to setup specific keywords to track on the Twitter Stream API. Upon configuring access to your Elasticsearch instance, results are then pushed to the database and can be visualised in Kibana like so:
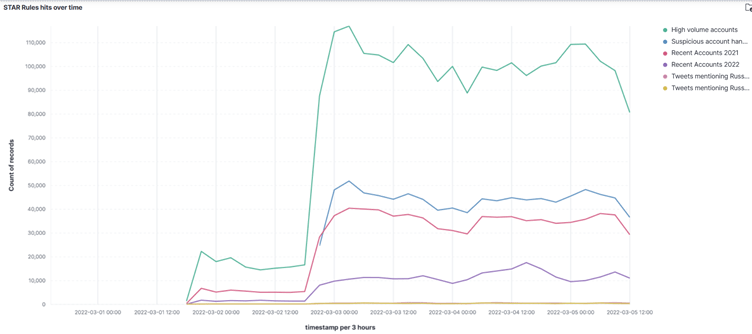
Analysis using STAR rules
Using STAR rules, you can then start to use a “funnelling” approach to collecting suspicious tweets. By using rules detecting atomic behaviours, you can then find a subset of tweets that have multiple corresponding behaviours, enabling you to find a subset of potential bad actors in real time. This allows researchers to significantly narrow down the number of accounts they are tracking to reveal a small subset of potential bad actors tweeting on relevant topics in real-time.
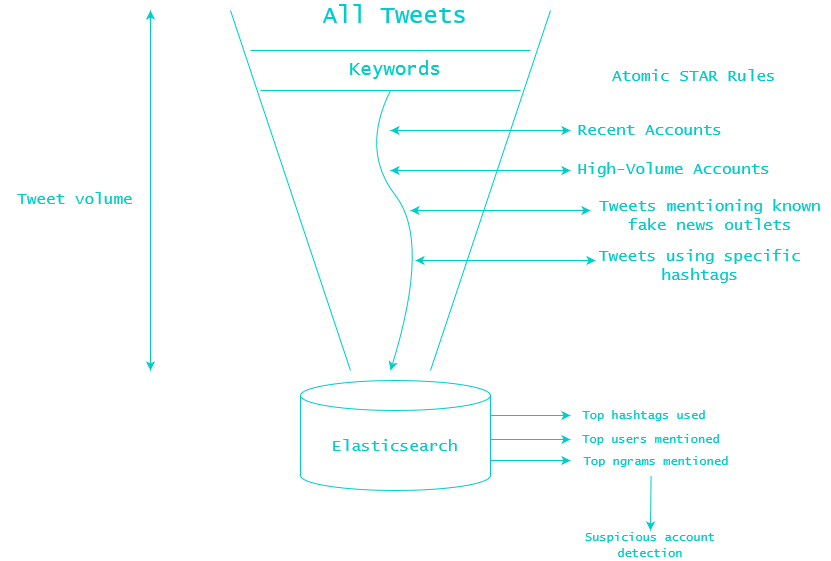
Funnelling approach to data collection

Finding a subset of threat activity from atomic STAR rules

Leave a comment